Kolejny post i znowu listy. Nie ma się co dziwić, tak jak pisałem, jest to jedna z najpopularniejszych struktur danych. Do tego ich implementacje w JavaScripcie są bardzo ciekawe i mogą wiele nauczyć o działaniu języka. Wersja, która omówię w tym poście w szczególności. Dziś w serii struktury danych w JavaScripcie – lista dwukierunkowa.

O zwykłej liście i liście jednokierunkowej opowiadałem w poprzednich wpisach. Zrozumienie tamtych struktur, jest kluczowe jeżeli chcesz zabrać się za pracę z listą dwukierunkową. Poziom abstrakcji, zaczyna wzrastać i dzisiejsza struktura może sprawiać wrażenie skomplikowanego tworu. W takim wypadku zachęcam do powrotu do poprzednich wpisów. Jeśli natomiast nie masz problemu ze zrozumieniem opisywanych przeze mnie wcześniejszych implementacji, to i tutaj nie powinno być problemu.
struktury danych w JavaScripcie – lista dwukierunkowa. Teoria.
Zanim przejdę do kodu, chciałbym poświęcić trochę miejsca na zdefiniowanie wszystkich właściwości i zachowań listy dwukierunkowej. Ta struktura danych jest podobna do swojej jednokierunkowej wersji, ma jednak jedną ważną różnicę. Węzły listy dwukierunkowej, oprócz wskaźnika kierującego do następnego elementu, posiadają także wskaźnik poprzedniego elementu. Poniżej schemat:

Lista ta posiada trzy elementy. Każdy z nich oprócz pola zawierającego dane, posiada też dwa pola zawierające wskaźniki. Jeden wskazujący na kolejny element a drugi na poprzedni. W kodzie będą one nazwane kolejno prev oraz next. Jak widać prev pierwszego elementu (zwanego głową listy), wskazuje na null. Tak samo dzieje się ze wskaźnikiem next ostatniego elementu (zwanego również ogonem listy).
Operacje na tej strukturze danych, będą wyglądały podobnie jak w liście jednokierunkowej. Program będzie poruszać się po liście za pomocą pętli aż trafi na element, który ma usunąć, lub na taki, przed którym ma umieścić nowy element. Jednak tym razem, elementy biorące udział w operacji, będą musiały zostać zaktualizowane na dwóch polach, next oraz previous.
Omówię dokładniej przebieg tych operacji. Najpierw usuwanie elementów z listy. Mamy tutaj trzy scenariusze. Pierwszy z nich to usuwanie elementu z początku listy. Oto schemat:
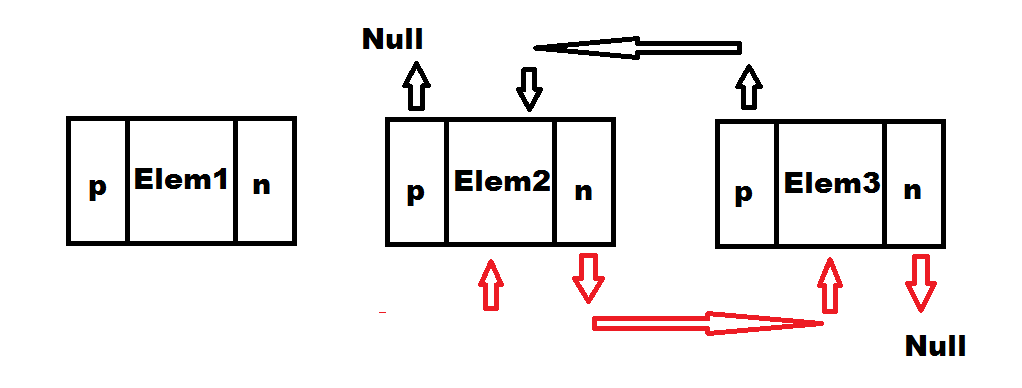
Jak widać nie jest to specjalnie skomplikowana operacja. Wystarczy zmienić wskaźnik drugiego z kolei elementu na null. Nic nie wskazuje już na pierwszy element, więc zostanie on usunięty z pamięci przez JavaScript. Jak łatwo się domyślić łatwo będzie dotrzeć do drugiego elementu, dzięki wskaźnikowi next pierwszego. Na koniec program, oznaczy drugi element jako nową głowę listy.
Drugi scenariusz na jaki może natrafić program podczas usuwania elementów, to usuwanie ostatniego węzła.
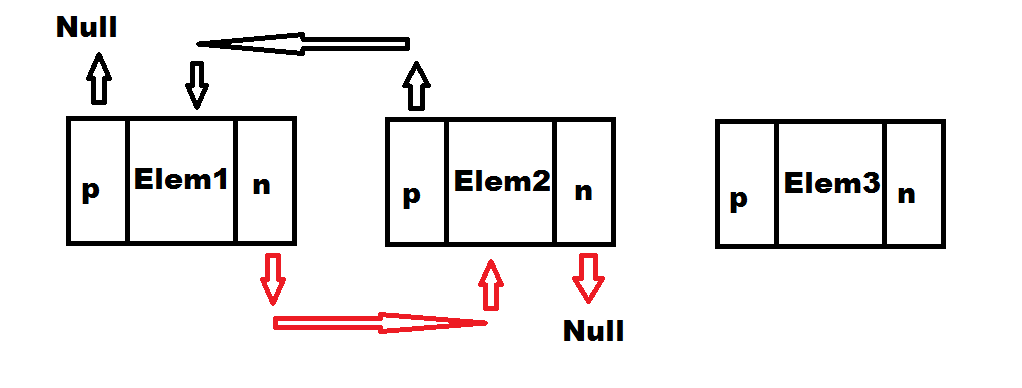
Tutaj sprawa jest analogiczna. Wskaźnik next ostatniego elementu zostaje ustawiony na null. Dzięki wskaźnikowi previous ogona listy, dostęp do przedostatniego węzła jest bardzo łatwy. Na koniec wystarczy zaktualizować zmienną reprezentującą ogon, tak aby wskazywała przedostatni element.
Trzeci scenariusz podczas usuwania elementów, to wszystkie pozostałe przypadki, czyli usuwanie węzłów ze środka listy.
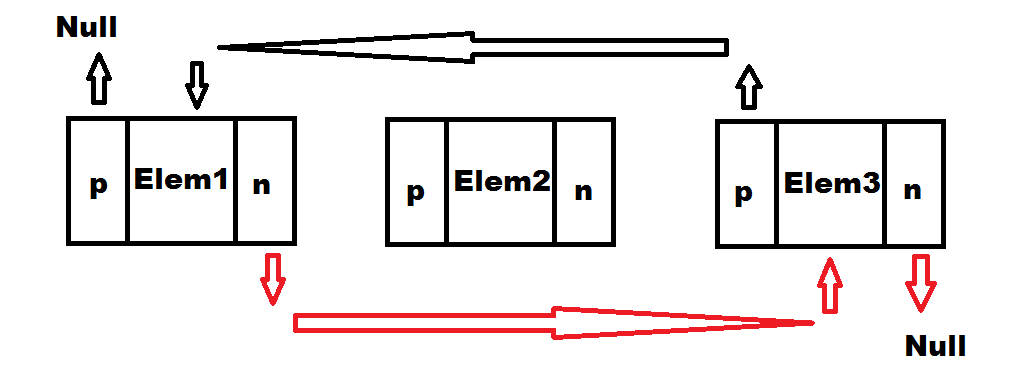
Po przeanalizowaniu dwóch poprzednich przypadków, ten powinien być oczywisty. Usuwanie elementu ze środka listy polegać będzie na zaktualizowaniu wskaźników poprzedniego i kolejnego węzła tak, aby wskazywały na siebie. Wskaźnik next elementu pierwszego wskazuje na element trzeci, a wskaźnik previous trzeciego na pierwszy. W ten sposób element drugi zostaje wyłączony z ‚łańcucha’.
Dodawanie nowych elementów również może odbyć się na trzy sposoby. W tym wypadku również od miejsca na liście, na które nowy element ma zostać dodany. Na początek schematy przedstawiające przyłączanie nowych węzłów na krańce listy.
początek:

koniec:

Fioletowe strzałki pokazują nowe połączenia. Wystarczy odpowiedni wskaźnik zmienić tak aby nie wskazywał null a nowy element. Następnie wskaźnik nowego elementu kierowany jest na poprzedzający/kolejny węzeł. Oczywiście program też ustawia nową wartość dla zmiennych reprezentujących głowę oraz ogon listy.
Dodawanie elementu wewnątrz listy wymaga trochę więcej operacji.
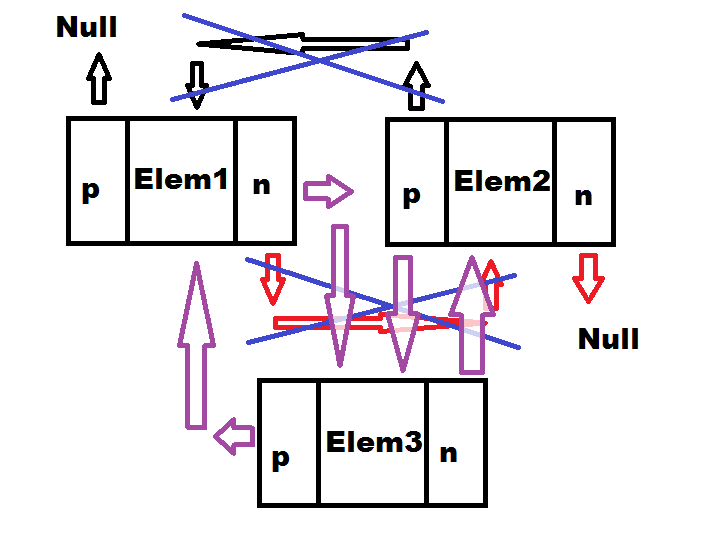
Czerwone i czarne strzałki to połączenia, które znajdują się w liście przed dodaniem nowego elementu. Przekreślone na niebiesko połączenia, to te, które są aktualizowane. Fioletowe strzałki reprezentują nowe połączenia, budowane podczas dodawania elementu. Oprócz ustawienia wskaźników previous oraz next nowego elementu, program aktualizuje także odpowiednie wskaźniki węzła poprzedzającego nowy, oraz tego węzła który znajduje się za nim.
Skoro teorię mam już za sobą czas na implementację w JavaScripcie.
struktury danych w JavaScripcie – lista dwukierunkowa. Kod.
Pisałem już kiedyś o tym, że zmienne w JavaScripcie mogą czasem zawierać dane a czasem referencję do innych obiektów. W tej implementacji jest to bardzo mocno wykorzystywane. W języku C prev oraz next nie byłyby zwykłymi zmiennymi. Byłyby to specjalne elementy języka, które wskazują na adres innej zmiennej. Dzięki specjalnym oznaczniem wiadomo, że mamy do czynienia ze wskaźnikiem. W JavaScripcie, niestety nie ma wyraźnej informacji o tym czy zmienna, która akurat operujemy jest typu referencyjnego czy prostego. Dlatego trzeba ze zmiennymi uważać, bo możemy czasem stworzyć dziwne błędy, których źródła nie łatwo jest wykryć 🙂 Najlepszym sposobem na unikanie błędów jest praktyka, a w tym przykładzie będzie sporo praktyki z typami referencyjnymi. To taka mała informacja ode mnie, na co warto zwracać uwagę w poniższym kodzie.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 |
var DoublyLinkedList = function(){ this.Node = function(element){ this.element = element; this.next = null; this.prev = null; }; this.size = 0; this.head = null; this.tail = null; this.view = function(){ var current = this.head; var string = ''; while(current) { string+= (current.element+", "); current = current.next; } if(string === '') { return "list is empty"; } else { return string; } }; this.append = function(element){ var node = new this.Node(element) if(this.size === 0){ this.head = node; this.tail = node; } else { this.tail.next = node; node.prev = this.tail; this.tail = node; } this.size++; }; this.viewAt = function(position){ if (position>= 0 && position<= this.size){ var current = this.head; var index = 0; while(position > index) { current = current.next; index++; } return current.element; } else { return "no such position on list" } }; this.insertAt = function(position, element){ var node = new this.Node(element); var current = this.head; var index = 0; var previous; if (position>= 0 && position<= this.size){ if(position===0){ if(this.size === 0) { this.head = node; this.tail = node; } else { node.next = this.head; this.head.prev = node; this.head = node; } } else if(position === this.size) { this.tail.next = node; node.prev = this.tail; this.tail = node; } else { while(index < position){ previous = current; current = current.next; index++; } node.next = current; previous.next = node; node.prev = previous; current.prev = node; } this.size++; } else { return false; } }; this.removeAt = function(position){ if (position>= 0 && position<= this.size){ var current = this.head; var index = 0; var previous; if(position === 0){ if(this.size === 1) { this.head = null; this.tail = null; } else { this.head = current.next; this.head.prev = null; } }else if(position === this.size-1) { current = this.tail; this.tail = current.prev; this.tail.next = null; } else { while(index < position) { previous = current; current = current.next; index++; } previous.next = current.next; current.next.prev = previous; } this.size--; } else { return false; } }; this.viewReverse = function() { var current = this.tail; var returnString = ''; if(this.size != 0){ while(current) { returnString += (current.element + ", "); current = current.prev } return returnString; } else { return "this list is empty"; } } }; |
Tak wygląda klasa dwukierunkowej listy. Pierwszy jej element to metoda/konstruktor Node służąca do tworzenia nowego węzła listy. Wygląda ona prawie tak samo jak w liście jednokierunkowej. Nowością jest pole prev, które wskazywać będzie na poprzedzający dany węzeł element. W przypadku gdy element będzie pierwszy na liście, to pole równać będzie się null.
Następne są pola obiektu. Oprócz znanych z lity jednokierunkowej pól size (rozmiar listy) i head (zmienna wskazująca umownie pierwszy element listy), jest też pole tail. tail to zmienna, która wskazywać będzie na węzeł, który umownie będzie ostatnim węzłem listy. Warto tutaj zaznaczyć, że jeżeli lista będzie miała tylko jeden element, będzie on wskazywany zarówno przez pole head jak i tail.
Metoda view działa identycznie jak w przypadku listy jednokierunkowej. Za to metoda append trochę się zmieniła. Ponieważ w tym wypadku pole tail daje nam bezpośredni dostęp do ostatniego elementu, sprawa dodania węzła na koniec listy jest znacznie prostsza. Na początku oczywiście tworzony jest nowy element przy pomocy konstruktora Node. Następnie, jeżeli lista zawiera więcej niż jeden element, program wykonuje następujące kroki. Pole next elementu, na który wskazuje obecnie tail wskazuje teraz na nowy element. Pole prev nowego elementu, wskazuje na element wskazywany przez zmienną tail. Na koniec tail zmieniony jest tak aby wskazywał na nowy element. I za pomocą tych trzech prostych kroków można dodać węzeł na koniec listy dwukierunkowej. Jeżeli w liście nie znajdują się jeszcze żadne elementy, sprawa jest jeszcze prostsza. Pola tail oraz head głównej klasy ustawione zostają tak aby wskazywały na nowy element. Po dodaniu nowego elementu program inkrementuje wartość pola size głównej klasy.
Metoda viewAt również działa tak samo jak w przypadku listy jednokierunkowej.
Kolejna metoda to insertAt. Służy ona do dodawania nowego elementu. Podobnie jak w liście jednokierunkowej, przyjmuje ona dwa parametry, pozycję nowego elementu oraz jego dane. Na początku tworzony jest nowy element, oraz zmienne pomocnicze. Następnie sprawdzam czy pozycja znajduje się w dozwolonym zakresie (czy istnieje element w liście na takiej pozycji). Tak jak ilustrowałem na schematach powyżej, istnieją trzy możliwości. Dodanie elementu na początku listy, na końcu lub w środku. Jeżeli jest to początek listy a lista nie zawiera innych elementów, pola head oraz tail wskazują teraz na head. Jeżeli nowy element ma być dodany na początku listy, która nie jest pusta, program ustawia pole next nowego elementu tak aby wskazywał na element wskazywany przez head. Następnie pole prev elementu wskazywanego przez head zmieniane jest aby wskazywało na nowy element. Na końcu program ustawia head tak aby wskazywał na nowy element.
Jeżeli nowy element ma zostać dodany na końcu listy, przebieg programu wygląda dokładnie tak samo jak w przypadku metody append.
Ostatni przypadek to dodanie nowego elementu wewnątrz listy. Używając pętli while oraz zmiennych pomocniczych, program iteruje przez listę. Wygląda to tak samo jak w przypadku listy jednokierunkowej. Gdy program dojdzie na odpowiednią decyzję pole next znajdującego się wcześniej elementu ustawiane jest aby wskazywało na nowy element. Pole prev również ustawiane jest tak aby wskazywało na nowy element. Pola next oraz prev nowego elementu ustawiane są tak aby wskazywały na to co trzeba 🙂 Na końcu oczywiście wartość pola size głównej klasy inkrementuje się.
Kolejna metoda removeAt, jak nazwa wskazuje, służy do usuwania elementów. Jak parametr przekazywana jest pozycja elementu do usunięcia. Jeżeli pozycja jest większa od zera i mniejsza od rozmiaru listy minus jeden (pozycje liczę od zera), program tworzy zmienne pomocnicze. W tym wypadku również istnieją trzy możliwości, tak jak na schematach przedstawionych powyżej. W przypadku gdy element ma zostać usunięty z początku listy i jest to jedyny element, program zmienia wartości pól head oraz tail na null. Jeżeli element usuwam z początku listy która ma już jakieś elementy, wystarczy zmienić pole head tak aby wskazywało na to na co zawiera pole next tego co obecnie wskazuje head (wiem, brzmi strasznie. W kodzie widać o co chodzi :)). Kolejny przypadek to usuwanie elementów z końca listy. Podobnie, zmieniam tail tak aby wskazywał na to na co obecnie wskazuje pole prev tego na co obecnie wskazuje tail. Trzeci scenariusz to usuwanie elementów ze środka listy. Program przeszukuje listę aż trafi na odpowiednią pozycję. Gdy już to zrobi wystarczy zmienić pole prev następnego elementu tak aby wskazywało na element przed wcześniejszy (warto przyjrzeć się w kodzie jak to wygląda), oraz pole next poprzedniego elementu tak aby wskazywało na następny.
Ostatniej metody nie będę opisywał szczegółowo. viewReverse stworzyłem głównie w celach testowania czy wszystkie połączenia prev działają jak należy. Metoda ta zachowuje się tak jak metoda view leczy wyświetla listę od końca.
I to tyle jeśli chodzi o listę dwukierunkową. Od tych wszystkich połączeń i wskaźników może zakręcić się w głowie. Dlatego dodałem na początku schematy aby w razie nie jasności pomogły w wyobrażeniu sobie zachodzących operacji. Oczywiście bardzo dobrze jest też studiować kod aby zobaczyć to na tak zwanym „żywym organizmie”.
Wpis wyszedł trochę długawy. Jeżeli udało Ci się go doczytać do końca, koniecznie daj znać w komentarzu żebym mógł przybić Ci wirtualną piątkę 😉
Mam nadzieję że wiadomości tu zwarte pomogą w zrozumieniu listy dwukierunkowej oraz w podniosą wasze umiejętności korzystania z JavaScriptu. W razie czego chętnie odpowiem na wszystkie pytania. Można je zadawać również w komentarzach pod postem oraz na mojej stronie na facebooku, którą aktualizuję na bieżąco (dlatego warto polubić 😉 ).